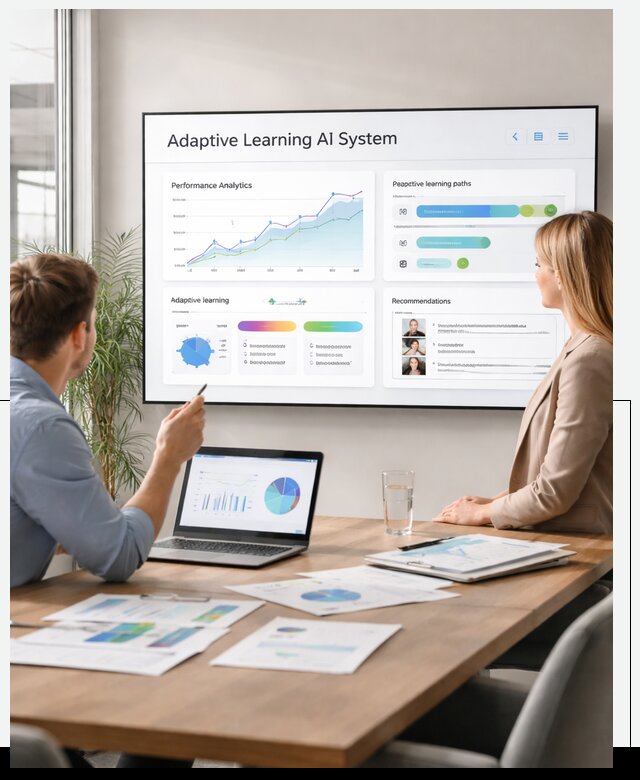
Какие ключевые компоненты включает адаптивная обучающая AI-система и как они взаимодействуют между собой
Адаптивная обучающая AI-система состоит из нескольких взаимосвязанных компонентов, каждый из которых отвечает за конкретный этап работы и обеспечивает адаптацию в реальном времени под поведение пользователя или изменение внешних условий. Основные компоненты и их роли:
1. Модуль сбора данных и интеграции источников данных — отвечает за агрегацию событий, логов, телеметрии, результатов оценок и метрик взаимодействия. Поддерживает подключение к базе данных, LMS, CRM и внешним API, нормализует формат входящих данных и передает дальше.
2. Слой предобработки и преобразования данных — включает в себя очистку, заполнение пропусков, агрегацию, извлечение признаков и масштабирование. Здесь применяются правила бизнес-валидации, детекция аномалий и маркеры контекста, позволяющие учитывать особенности курса или продукта.
3. Модель адаптации и рекомендаций — ядро системы, где используются гибридные подходы: коллаборативная фильтрация, контентные модели, модели на основе обучения с подкреплением и нейронные сети для персонализации траекторий обучения. Модель получает сигналы от модуля обратной связи и корректирует планы обучения в режиме онлайн.
4. Модуль управления контентом и логики курса — обеспечивает организацию уроков, модулей, контрольных точек, ветвлений траекторий и правил перехода между уровнями. Позволяет устанавливать бизнес-правила, ограничения по времени и условия перехода.
5. Система мониторинга и A/B-экспериментов — отслеживает KPI эффективности обучения, вовлеченности и качества усвоения, поддерживает проведение экспериментов для оценки гипотез и непрерывного улучшения модели.
6. Интерфейс адаптации и визуализация — предоставляет преподавателям и администраторам инструменты для настройки адаптивной логики, просмотра тепловых карт, прогрессов и рекомендаций. Позволяет экспортировать отчеты и интегрировать их в существующие панели мониторинга.
7. Модуль приватности и соответствия — контролирует доступ, логи, шифрование данных и обеспечивает соответствие требованиям регуляторов. Взаимодействие компонентов организовано через API и очереди сообщений, что обеспечивает масштабируемость и отказоустойчивость. Такой модульный подход позволяет гибко адаптировать систему под разные отрасли и сценарии использования, минимизируя время интеграции и повышая точность персонализации.
Какие требования к данным и какие этапы предобработки необходимы для корректной работы адаптивной AI-системы
Для эффективной работы адаптивной AI-системы критически важно обеспечить качество, полноту и релевантность входных данных. Требования и этапы предобработки включают следующие элементы:
1. Типовые источники данных: взаимодействия пользователей (клики, просмотры, ответы на тесты), профили пользователей (демография, роль, навыки), контентные метаданные (темы, теги, сложность), бизнес-метрики и внешние данные (временные ряды, сезонность).
2. Валидация целостности и полноты: проверка отсутствующих полей, корректности типов данных, контроль на дубли и неконсистентные записи. Нужна логика заполнения пропусков и правила отклонения заведомо неверных значений.
3. Детекция и обработка аномалий: алгоритмы выявляют выбросы по активности, резкие скачки и неадекватные паттерны, которые могут испортить обучение модели. Для таких случаев применяются фильтры или отдельная маршрутизация данных на ручную проверку.
4. Преобразование и нормализация признаков: кодировка категориальных переменных, масштабирование числовых показателей, создание временных признаков (частота, время суток, день недели), агрегация поведенческих метрик за скользящие окна. Эти этапы критичны для стабильного обучения моделей машинного обучения и нейронных сетей.
5. Генерация дополнительных признаков (feature engineering): контекстуальные индикаторы прогресса, индексы сложности контента, оценки усвоения, синтетические признаки для моделирования межпредметных зависимостей. Хорошая генерация признаков повышает объяснимость и точность рекомендаций.
6. Балансировка выборки и подготовка для обучения: в задачах персонализации часто требуются техники ресэмплинга, стратифицированные разбиения и создание валидационных наборов, учитывающих временную составляющую и возможные смещения данных.
7. Постоянная поддержка качества данных: внедрение пайплайнов ETL/ELT, мониторинг дрейфа распределений, автоматические алерты и процедуры ретренинга моделей при изменении бизнес-условий. Такой подход позволяет сохранять корректность адаптации в долгосрочной перспективе и обеспечивает устойчивость AI-системы к изменению поведения пользователей.
Как происходит персонализация траекторий обучения и какие алгоритмы используются для адаптации под каждого пользователя
Персонализация траекторий обучения опирается на сочетание статистических методов, машинного обучения и алгоритмов обучения с подкреплением, что позволяет формировать динамические планы, оптимизированные под цели и поведение конкретного ученика. Основные шаги процесса персонализации:
1. Построение профиля пользователя: сбор explicit- и implicit-данных, включая предпочтения, предыдущие результаты, скорость прохождения, зоны затруднений и мотивационные параметры. Профиль обновляется в реальном времени после каждого взаимодействия.
2. Кластеризация и сегментация: на основе признаков формируются кластеры пользователей с похожими паттернами обучения. Это позволяет ускорить персонализацию при недостатке индивидуальных данных, применяя гибридный подход: общая стратегия для кластера + тонкая настройка под пользователя.
3. Рекомендательные алгоритмы: используются контентные фильтры для сопоставления материалов по темам и сложности, коллаборативные модели для рекомендаций на основе схожих пользователей, и мета-алгоритмы для объединения сигналов. Для решения задач последовательного выбора контента применяются рекуррентные нейронные сети и трансформеры, способные учитывать историю взаимодействий.
4. Обучение с подкреплением (Reinforcement Learning): используется для оптимизации долгосрочных целей — удержания, глубины усвоения, достижения компетенций. Агент выбирает следующий элемент обучения, получает метрику вознаграждения (например, улучшение результатов теста через N сессий) и корректирует политику действий для максимизации кумулятивного эффекта.
5. Онбординг и холодный старт: для новых пользователей применяются эвристики, анкеты и быстрая диагностическая сессия для первичной настройки адаптации. Затем система постепенно переходит на полностью персонализированные модели по мере накопления данных.
6. Замкнутый цикл обратной связи: постоянный сбор метрик эффективности, A/B-тестирование новых стратегий, и автоматическое ретренирование моделей. Инструменты объяснимости моделей (XAI) используются для интерпретации рекомендательных решений перед преподавателями или пользователями.
7. Практическая реализация: архитектура поддерживает микросервисы, онлайн-реплейсмент моделей и гибкие правила бизнес-логики, что обеспечивает быструю подстройку под изменения и интеграцию с LMS. Такой набор подходов обеспечивает персонализацию, учитывающую не только текущую компетенцию, но и мотивационные и поведенческие факторы пользователя.
Какие подходы к интеграции и масштабированию внедрения адаптивной AI-системы в существующую IT-инфраструктуру организации
Интеграция адаптивной AI-системы требует планирования на уровне архитектуры, безопасности и процессов. Рекомендуемые подходы и практические шаги включают:
1. Оценка текущей инфраструктуры и интерфейсов: инвентаризация LMS, CRM, ERP, систем аутентификации и хранилищ данных. Анализ пропускной способности, ограничений по API и политик безопасности дает понимание степени изменений, которые потребуются.
2. Модульность и API-first дизайн: система должна предлагать четко документированные REST/GraphQL API и события через очереди сообщений (Kafka, RabbitMQ) для интеграции в реальном времени. Это позволяет подключать адаптивную логику поэтапно, минимизируя влияние на текущие процессы.
3. Контейнеризация и оркестрация: использование контейнеров (Docker) и оркестраторов (Kubernetes) обеспечивает масштабирование ресурсов под нагрузку, высокую доступность и удобство деплоя. Горизонтальное масштабирование микросервисов для обработки потоков данных и моделей важно при росте числа пользователей.
4. Стратегия развертывания: поэтапное внедрение — пилот на малой группе, параллельная работа с текущей системой, A/B-тесты и постепенное расширение охвата. Такой подход снижает риски и позволяет собирать реальные метрики для корректировки решений.
5. Интеграция данных и ETL-пайплайны: должны поддерживаться безопасные каналы передачи данных, регулярные синхронизации и поддержка потоковой обработки для реального времени. Резервные копии и планы восстановления обеспечивают целостность данных.
6. Обеспечение безопасности и соответствия: настройка авторизации через SSO, шифрование данных в покое и при передаче, аудит логов и управление доступом по ролям. Для соответствия нормативам требуется внедрять механизмы удаления и анонимизации персональных данных.
7. Поддержка и мониторинг: системы логирования, метрики производительности, мониторинг моделей (drift detection) и алерты для быстрой реакции на деградацию качества. Сопровождение включает обновления моделей, регулярные реструктуризации и обучение персонала.
8. Стоимость и операционные модели: оценка TCO с учетом затрат на хранение данных, вычислительные ресурсы и сопровождение. При необходимости можно применять гибридную модель — облачные вычисления для обучения и локальные решения для хранения чувствительных данных в Сахалинской области. Отдельно оговариваются SLA и сценарии восстановления. Такой план интеграции обеспечивает управляемый рост системы и защиту инвестиций.
Как обеспечивается безопасность, конфиденциальность и соответствие нормативным требованиям при работе адаптивной обучающей AI-системы
Безопасность и соответствие — ключевые аспекты при внедрении AI-систем в образовательной и корпоративной среде. Основные меры и практики, которые мы реализуем, включают следующие направления:
1. Контроль доступа и аутентификация: внедрение многофакторной аутентификации, управление правами через IAM/ RBAC, интеграция с корпоративными SSO-провайдерами. Ограничение доступа к данным на уровне сервисов и ролей минимизирует риск утечки. Мы работаем Пн1-Пт 09-18 Сб-Вс вых. и можем гибко настраивать режимы доступа под рабочие часы и сценарии.
2. Шифрование и защита данных: применение шифрования на транспортном уровне (TLS) и в состоянии покоя (AES-256). Для чувствительной персональной информации используются методы псевдонимизации и анонимизации, а также отдельные хранилища с повышенными требованиями по доступу.
3. Управление жизненным циклом данных: политика хранения и удаления данных, журналы аудита, резервное копирование и процедуры восстановления. В соответствии с регуляторными требованиями реализуем механизмы удаления по запросу и прозрачные логи событий доступа.
4. Соответствие стандартам и нормативам: подготовка документации и сопутствующих процедур для соответствия отраслевым требованиям, внутренним политикам и законодательству по защите данных. В случае необходимости адаптируем решения под локальные стандарты в Южном-Сахалинске.
5. Верификация и тестирование безопасности: регулярные тесты на проникновение, статический и динамический анализ кода, ревью конфигураций и проверка зависимостей. Модели проходят оценку на предмет уязвимостей и возможных атак на данные или модель (model poisoning, data leakage).
6. Прозрачность и объяснимость: внедрение инструментов XAI для объяснения решений моделей преподавателям и администраторам, что облегчает аудит и принятие корректирующих мер при некорректных рекомендациях. Это повышает доверие к системе и помогает соблюдать этические требования.
7. Обучение и процедуры для персонала: разработка регламентов, обучение сотрудников и пользователей правилам безопасной работы с системой, реагирования на инциденты и обработке персональных данных. Отправьте запрос КП Григорию Георгиевичу для получения подробных регламентов по безопасности и внедрению.
Компания АвикейЮжн работает с 2011 года и обеспечивает комплексный подход к безопасности и соответствию. При заказе услуги под ключ скидка от 15 процентов. Для оперативной связи используйте телефон +7 936 252-33-89. С 2011 года по 2026 вополнено более 4391 заказов